
SnapshotCM Definitions
Introduction
SnapshotCM melds several concepts, some new and some borrowed, to provide a solution that abstracts the complexities and improves the understanding of software configurations. This document defines these concepts and the terminology and nuances specific to SnapshotCM, as well as how these concepts are meant to fit together in SnapshotCM.
In the big picture, SnapshotCM is about helping you manage changes to files you care about. The key words here are you, changes and files. SnapshotCM helps you by implementing high-level concepts to help you understand and manage the state of your files, and high-level operations to free you from the detailed manipulations required of many CM systems. SnapshotCM provides advanced team coordination concepts that structure and control changes to your data. Team members can work in isolation or in groups, can publish their changes to others and synchronize easily with changes others have published, all with flexibility appropriate to the task at hand. Finally, SnapshotCM manages files and directories, and changes to any of their attributes (content, name, parent directory, text/binary type, keyword expansion mode, unix mode, and existence).
The rest of this document is a top-down definition of the terminology of SnapshotCM.
SnapshotCM Architecture
|
SnapshotCM ServerThe SnapshotCM server/data store manages zero or more projects and the SnapshotCM accounts used for authentication and authorization of accesses. We will talk about accounts and the data store later. |
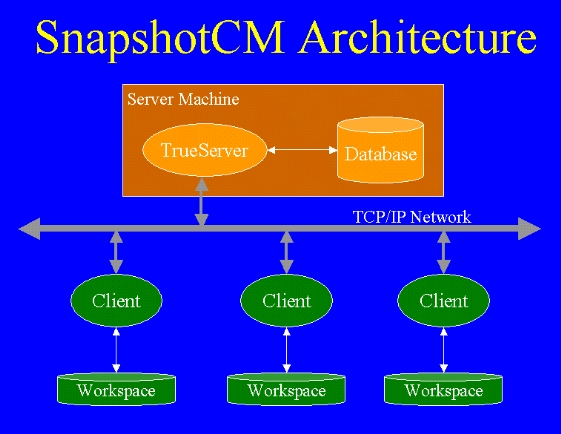 Figure 1 shows the
high-level SnapshotCM architecture. The repository server manages the project
data and provides access to that data to SnapshotCM clients. SnapshotCM clients
interact with the SnapshotCM server to manipulate project data as well as
manage the private data in a SnapshotCM workspace. The key point here is that
all interaction with the project database involves SnapshotCM clients
interacting through the network with the SnapshotCM server.
Figure 1 shows the
high-level SnapshotCM architecture. The repository server manages the project
data and provides access to that data to SnapshotCM clients. SnapshotCM clients
interact with the SnapshotCM server to manipulate project data as well as
manage the private data in a SnapshotCM workspace. The key point here is that
all interaction with the project database involves SnapshotCM clients
interacting through the network with the SnapshotCM server.SnapshotCM Project
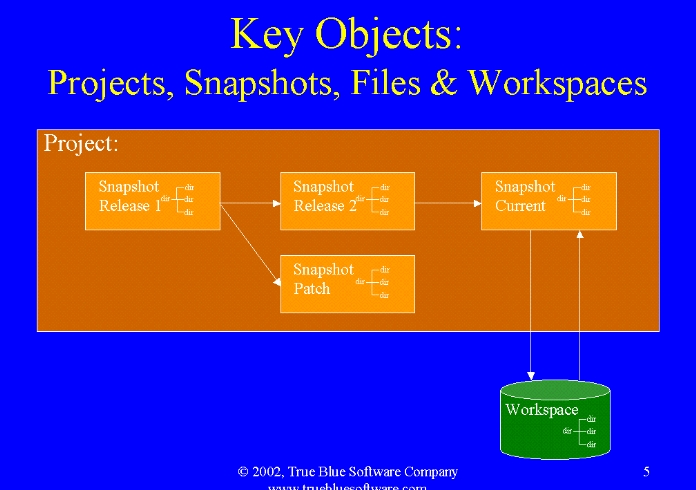
In
SnapshotCM, a project is the top-level container for a collection of related
files. Each server/data store can manage multiple projects. Projects do not
span multiple servers. A project name is a non-empty, nul terminated string
containing any character except slash. A project path is a slash followed by
the project name (eg. /Teddy Bear or /widget). Project names
are case sensitive.
Snapshot
A snapshot is a container holding a version of the project's files. Each project contains one or more snapshots. A snapshot name is hierarchical, appended to the project name. Each element of the name is separated from the other by a slash (eg. /widget/release 1 or /Teddy Bear/next/GUI). There are two types of snapshots which differ primarily in their intended use.
Release Snapshot
A Release snapshot is a top-level snapshot. The full name of a release snapshot is the project path followed by a slash and the release snapshot name (eg. /widget/release 1). Release snapshots are allowed to have sibling relationships (directed graph, many to many) to other release snapshots. Release snapshots and their sibling relationships are shown graphically in the SnapshotCM GUI. As their name implies, release snapshots are designed to represent project releases. Each time a project is released, a separate release snapshot should be created to preserve the state of the project as just released. On-going work for future releases should also have distinct release snapshots. The release snapshot relationships are designed to show the relationships between the project releases.
Development Snapshot
A Development snapshot is a snapshot with multiple components in its name. A development snapshot is a child of a release or another development snapshot. The full name of a development snapshot is the project path followed by a slash and the snapshot name (eg. /widget/next/GUI). Development snapshots are designed to represent in-progress work awaiting release. And the hierarchy of development snapshots (with a release snapshot as its root) is designed to provide a structure for coordinating a team's work.
Workspace
A workspace is a directory hierarchy on a client system which is associated with one or more snapshots. It has a name (any string unique to the user on this system) and a few other attributes. A workspace is where a user interacts with the associated snapshot files to accomplish his work. SnapshotCM uses the long transaction check out—modify—check in model for content changes, and direct attribute editing, affecting both the workspace and snapshot files, for attribute changes. In the promotion model, a workspace is at the leaf.
The key to understanding how all the snapshots and workspaces work together is the SnapshotCM Promotion Model.
Promotion Model
The promotion model describes how workspaces and the snapshots in a snapshot hierarchy are related. SnapshotCM is designed so that each developer or sub-team will have their own development snapshot that only they use. Attached to that will be one or more workspaces that only that developer uses. Since each snapshot represents a distinct version of the project files, each individual will be isolated from other's changes until a time convenient for that developer. When a change is completed, changes made by others can be integrated into the developer's snapshot and workspace and the finished change published for other team members to pick up.
The isolation provided by giving each individual a separate snapshot allows a change to be completed and released as a unit. Intermediate results can be accumulated using the full version control functionality and then released as a unit.
Within a development hierarchy, there are child and parent relationships. SnapshotCM is designed for changes to be propagated along the parent-child relationships. The recommended configuration will arrange the snapshots such that the leaf snapshots are assigned to individuals, their immediate parents assigned to sub-teams or teams, and so on to the top level (release) snapshot. This example illustrates this by using roles for each component name:
/project/release/integration/subteam/individual
As changes are made and promoted up the hierarchy toward the release snapshot, increasing levels of integration and stability are expected.
SnapshotCM Accounts
SnapshotCM accounts are used for authentication (telling SnapshotCM who you are) and authorization (controlling what you can do). Once authenticated, the client is associated with a specific SnapshotCM user account, plus one or more group accounts. Each controlled object contains an ACL with 0 or more user or group ids and associated authorization.
SnapshotCM Data Store
The SnapshotCM data store consists of two parts: the versioned file archive and the meta-data dbms. The versioned file archive stores file contents. All versions of all files managed by the SnapshotCM server are stored here. The dbms stores all other project and account information. Updates to the data store are performed using reliable transactions coordinated by the server. The data store contains shared data, while workspaces contain private data.
Workspace Data
A SnapshotCM workspace stores a lot of meta information about contained files. A SnapshotCM workspace stores where files in the workspace came from so it can tell if the file attributes in the snapshot have changed such that the local file becomes out-of-date and in need of updating. SnapshotCM also stores attributes of the local file at check out time so as to know if the local file has been modified and in need of being checked in. Of course, if both occur, a merge is needed. All this data is private to the workspace. In fact, the server knows nothing of workspaces, except that the server does keep a list of locks, and locks contain information that the client can use to recover from deleted workspace meta data. The workspace private data is stored in a file by the name of .cache.SnapshotCM located in a snapshot mount directory in the workspace.
