
Technical Concepts
In this document, we discuss five key concepts or different ways of thinking that undergird SnapshotCM.
1. Files that Branch vs. Branches with Files
The Problem
The typical CM system manages files which contain many revisions. Parallel development is handled by creating branch revisions in each file which diverges.
A configuration selection then involves selecting the files of interest, and for each selected file, choosing which revision (or branch) to access. Altogether, 2n choices must be made. Since this is beyond human ability when dealing with more than a few files, we usually select all files, and either the latest or some tagged revision of each file. But even when choosing a tagged revision, the list of valid tags is not visible, and only the more sophisticated toolsets provide robust ways of managing the tags on all the files.
One fundamental problem with this typical solution is that the conceptually simple idea of branching -- give me a copy I can work on in isolation -- has been encumbered with particular implementation choices that the user must explicitly manage.
And even in systems that automate many of these choices, the distributed nature of the revision selection information (and the fact that tags can be easily modified) leaves thousands of points of failure. A "preserved" set of revisions today, may be worthless tomorrow.
Finally, the majority of the possible revision combinations have no logical consistency--they are meaningless, illegal, or perhaps worst of all -- subtly misleading.
The Solution
SnapshotCM from True Blue Software has gone back to the basics. Rather than selecting from the many revisions of thousands of files, in SnapshotCM you select which branch of the system to operate on, and the files AND revisions that correspond to that branch are automatically selected. You choose from a small number of meaningful branches (we call them snapshots) rather than from among thousands of files and revisions, where most combinations have no meaning. This simplification is possible because each snapshot keeps the list of files and revisions, and as changes are made, the list evolves until it becomes something you want to save. In effect, each snapshot represents a meaningful instance of the directories, files and attributes of a project.
By directly implementing the branch concept, SnapshotCM makes it as easy to do parallel development on thousands of files as to do parallel development on a single file in the old way. Yet, it has such low overhead that it is easy (even fun) to use it for small projects.
2. Snapshots
In SnapshotCM, snapshots (our term for branches) manage all product information. Snapshots map to workspaces. A workspace is a projection (or mapping) of all or part of one or more snapshots onto a local file system, together with local changes to those files. The names, attributes and contents of the files are copied to the workspace as specified in the snapshot. The user simply chooses which snapshots and where to put them in the workspace, and SnapshotCM does the rest.
Each snapshot represents an instance of a project and isolates one set of changes from another. That is, changes made to a snapshot are isolated to that snapshot. Explicit action is required to copy changes between snapshots.
Snapshots can be organized into promotion hierarchies. The snapshots at the root are called Release Snapshots, reflecting that whole releases are represented by top level snapshots. Changes can be checked in directly to Release Snapshots, or they can be made in child Development Snapshots and promoted into the Release Snapshot at a later time. The promotion hierarchy of snapshots provides a straightforward way of isolating changes until they are ready for wider distribution. Its also useful for maintaining a set of project versions with various states of stability and functionality, and for coordinating changes from multiple teams.
In short, in SnapshotCM one makes changes in workspaces, checks them in to snapshots, and then promotes changes to the top of the snapshot hierarchy until the top-level snapshot becomes ready to ship.
3. Operations
Small teams can operate effectively with a single snapshot per release. Multiple snapshots in SnapshotCM provide powerful solutions to complex environment needs because they support a powerful set of operations. Snapshots can be branched, compared and merged together. Changes made to one snapshot can easily be copied into another. A picture shows this best:
Release Snapshot
| |
Merge | /|\
| |
\|/ | Promote
v |
Development Snapshot
| |
Update | /|\
| |
\|/ | Check-in
v |
Workspace
Merge involves bringing changes down the promotion hierarchy from one snapshot to another, resolving conflicts as they occur. Promote pushes changes back up the hierarchy. If conflicting changes are present, they must be resolved during a merge. This is the classic concurrent development model and serves to make the promote a simple operation, rather than possibly involving significant merge effort and the resulting instability higher up the hierarchy.
Update is analogous to merge, only it updates a workspace with changes pending in a snapshot.
Check in is also familiar, incorporating changes from a workspace into a snapshot. Like promote, conflicts must be resolved in the workspace before check in.
4. Efficiency
SnapshotCM manages the complexity of configuration management so you can focus on your product. That alone makes it efficient. But it is legitimate to ask how fast and space efficient is SnapshotCM, especially since each snapshot acts as an independent copy of all the files and attributes in a project. SnapshotCM's implementation uses copy on write semantics to share revision contents, file names and attributes between copies of snapshots. This means that each snapshot only stores the differences from another snapshot, even though it appears to have the entire contents. Because of this, comparing two snapshots is also efficient (that which is truly shared can't be different), taking time proportional to the size of the difference rather than the total size of the snapshots involved.
Put another way, each snapshot can be looked at as a branch of the entire project, done efficiently, but with all the gory details managed automatically. SnapshotCM can easily manage thousands of snapshots.
5. Projects
In the simplest case, a SnapshotCM Server manages a single project with a single snapshot. But multiple projects each with multiple snapshots are also supported. Projects are independent of each other. That is, projects don't share files or revisions.
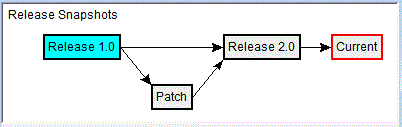
Within a project, multiple snapshot/workspace promotion hierarchies can easily exist, all referencing shared information where possible. The project keeps track of the list of top level Release Snapshots and their relationships, and can be used for comparing and merging forward patches into follow-on releases. This view of the releases is a logical place to represent release plans. For example, assuming version 1.0 is just released, we would represent concurrent development as at right:
The two paths from Release 1.0 represent two development streams. The arrow from Patch into Release 2.0 shows that Release 2.0 is intended to pick up all Patch changes. Being able to represent the actual reality of past releases and to plan for future releases graphically is one of the key benefits of SnapshotCM. Users can see how their work fits into the big picture, and these relationships support simple queries (for example, has Patch been merged into Release 2.0 yet). The release graph powerfully yet simply communicates key project information to all users.
